서론
프로그래머스 대장균의 크기에 따라 분류하기 2 문제를 풀면서 비율을 구하는데 기존에 알고 있는 아이디어로는 해결하기 어려웠습니다.
데이터의 비율을 계산하기 위한 PERCENT_RANK()에 대하여 알아보겠습니다.
PERCENT_RANK()
[PERCENT_RANK() 함수란?]
PERCENT_RANK()는 PARTITION 또는 RESULT SET내에서, 행의 Percentile Rank(백분위수 순위)를 계산하는 Window 함수 입니다.
[Syntax]
PERCENT_RANK()의 기본 Syntax는 다음과 같습니다.
PERCENT_RANK() OVER (
PARTITION BY partition_expression
ORDER BY
sort_expression [ASC | DESC]
)[작동 방식]
PERCENT_RANK() 함수는 0에서 1 사이의 숫자를 반환합니다.
지정된 행에 대해 PERCENT_RANK()는 해당 행의 순위에서 평가된 PARTITION 또는 쿼리 RESULT SET의 행 수에서 1을 뺀 값을 1로 나눈 값을 계산합니다.
(rank - 1) / (total_rows - 1)- 이 공식에서 rank는 지정된 행의 순위이고 total_rows는 평가 중인 행의 수입니다.
PARTITION 또는 RESULT SET의 첫 번째 행에 대해서는 PERCENT_RANK() 함수가 항상 0을 반환합니다. 반복되는 열 값은 동일한 PERCENT_RANK() 값을 받습니다.
다른 Window 함수와 마찬가지로 PARTITION BY 절은 행을 파티션으로 분배하고 ORDER BY 절은 각 파티션에 있는 행의 논리적 순서를 지정합니다. PERCENT_RANK() 함수는 정렬된 각 파티션에 대해 독립적으로 계산됩니다.
PARTITION BY 및 ORDER BY 절은 모두 선택 사항입니다. 그러나 PERCENT_RANK() 함수는 순서에 민감한 함수이므로 항상 ORDER BY 절을 사용해야 합니다.
예시
MySQL의 Sample 데이터베이스의 sakila 데이터베이스를 이용하여 PERCENT_RANK() 함수를 사용하면 어떻게 나타나는지 눈으로 확인해보겠습니다.
actor 테이블의 모든 데이터 구경하기
SELECT * FROM actor;
- 200여명의 배우 정보를 확인할 수 있습니다.
last_name으로 내림차순 정렬하고,
PERCENT_RANK()함수 적용해보기SELECT actor_id, first_name, PERCENT_RANK() OVER ( ORDER BY last_name DESC ) AS per FROM actor ORDER BY actor_id;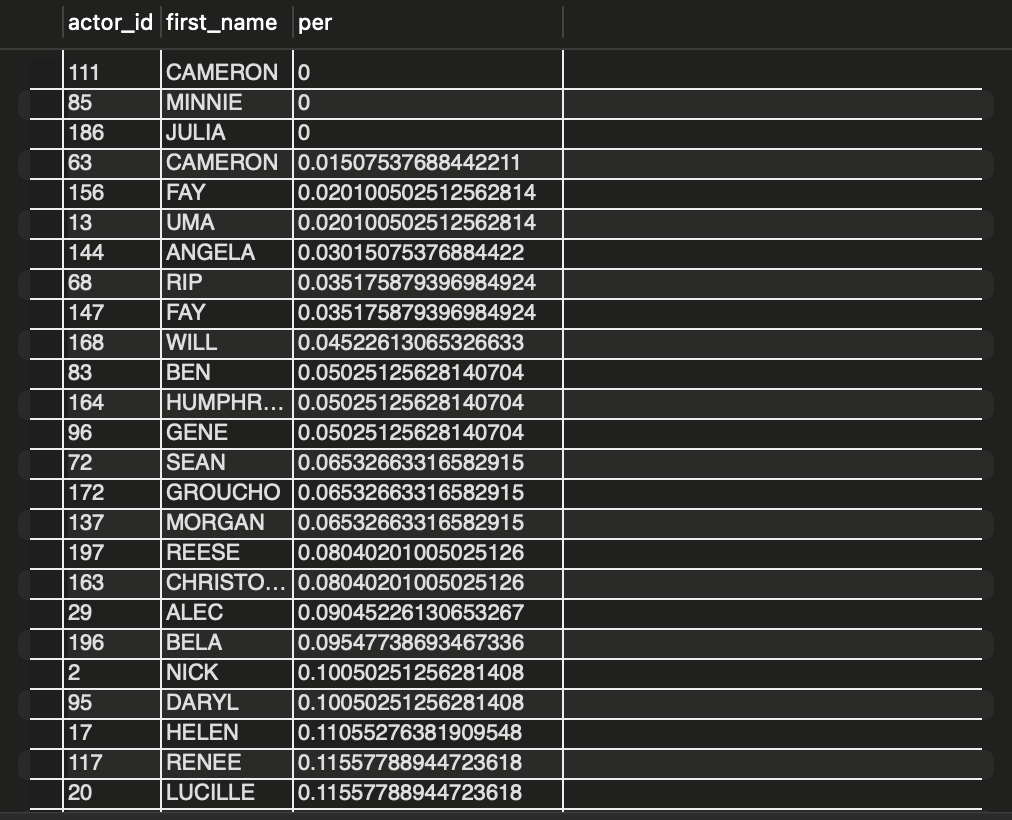
- 진짜 0과 1 사이의 값들이 나타나는 것을 확인할 수 있고, 첫번째 행과 반복되는 열 값은 0으로 나타나는 것을 확인할 수 있습니다.
문제 풀이
앞서 소개한 프로그래머스 대장균의 크기에 따라 분류하기 2 문제를 소개해드리면서, PARTITION_RANK() 함수를 이용해보겠습니다.
[문제]
대장균 개체의 크기를 내림차순으로 정렬했을 때 상위 0% ~ 25% 를 'CRITICAL', 26% ~ 50% 를 'HIGH', 51% ~ 75% 를 'MEDIUM',
76% ~ 100% 를 'LOW' 라고 분류합니다.
대장균 개체의 ID(ID) 와 분류된 이름(COLONY_NAME)을 출력하는 SQL 문을 작성해주세요.
이때 결과는 개체의 ID 에 대해 오름차순 정렬해주세요.
단, 총 데이터의 수는 4의 배수이며 같은 사이즈의 대장균 개체가 서로 다른 이름으로 분류되는 경우는 없습니다. [풀이]
대장균 개체의 크기를 특정 백분위로 분류하여 각각 'CRITICAL', 'HIGH', 'MEDIUM', 'LOW'로 분류해야 하기 때문에, PARTITION_RANK()를 사용합니다.
PARTITION_RANK() OVER (
ORDER BY SIZE_OF_COLONY DESC
) SIZE_RANKSIZE_OF_COLONY를 내림차순으로 정렬한 뒤, 각 행의 백분위를 0과 1 사이의 수로 반환해줄 것입니다.
PERCENT_RANK를 계산한 값들을, WITH 절을 이용해 공통 테이블 표현식(Common Table Expression, CTE)로 임시 테이블을 생성하여 저장합니다.
WITH RANK_DATA AS (
SELECT ID, PERCENT_RANK() OVER (
ORDER BY SIZE_OF_COLOLY DESC
) SIZE_RANK
FROM ECOLI_DATA
)이후에, RANK_DATA의 SIZE_RANK 열에는 백분위에 따른 0과 1 사이 값들이 저장되어 있기에, 문제에서 요구한 조건에 따라 조건을 분기해주면 됩니다.
CASE
WHEN SIZE_RANK <= 0.25 THEN "CRITICAL"
WHEN SIZE_RANK <= 0.50 THEN "HIGH"
WHEN SIZE_RANK <= 0.75 THEN "MEDIUM"
ELSE "LOW"
END COLONY_NAME[정답]
WITH RANK_DATA AS (
SELECT ID, PERCENT_RANK() OVER (
ORDER BY SIZE_OF_COLOLY DESC
) SIZE_RANK
FROM ECOLI_DATA
)
SELECT ID, CASE
WHEN SIZE_RANK <= 0.25 THEN "CRITICAL"
WHEN SIZE_RANK <= 0.50 THEN "HIGH"
WHEN SIZE_RANK <= 0.75 THEN "MEDIUM"
ELSE "LOW"
END COLONY_NAME
FROM RANK_DATA
ORDER BY ID;