
흔히들 Java는 Primitive 타입은 Pass-By-Value(Call-By-Value), Reference 타입은 Pass-By-Reference로 동작한다고 생각한다. 나 또한 그렇게 생각했다.
그러나 이것은 완전히 틀렸다.
Java는 오직 Pass-By-Value로 동작한다. 어째서일까? 함께 알아보도록 하자.
(참고 : 1. stackoverflow #40480 , 2. 망나니개발자 블로그, 3. Scott Stanchfield 블로그)
문제
import java.util.Arrays;
public class JavaExample {
public static void main(String[] args) {
int x = 10;
int[] arr = new int[]{1, 2, 3};
Person person1 = new Person("여민수");
Person person2 = person1;
foo(x, arr, person1);
// 2
System.out.println("#2 " + x);
// 3
System.out.println("#3 " + Arrays.toString(arr));
// 4
System.out.println("#4 " + person1.getName());
// 5
System.out.println("#5 " + person2.getName());
}
static void foo(int x, int[] arr, Person person) {
x ++;
arr[0] = 100;
person = new Person("김병수");
// 1
System.out.println("#1 " + person.getName());
person.setName("김준서");
}
static class Person {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
}해당 코드에 주석이 달린 1번부터 5번 순서대로, 어떻게 출력될 지 예측 해보자.
실행 결과
#1 김병수
#2 10
#3 [100, 2, 3]
#4 여민수
#5 여민수이러한 출력이 나오는 이유는 뭘까? 바로 Java는 Pass-By-Value로 동작하기 때문이다.
Pass-By-Value란?
Pass-By-Value(Call-By-Value)는 파라미터가 넘어올 때, 원본 데이터 값을 복사하여 넘기는 방식이다. 호출 된 메소드에서 해당 파라미터의 데이터를 변경하더라도 원본 데이터는 변경되지 않는다는 특징이 있다.
Pass-By-Reference란?
Pass-By-Reference(Call-By-Reference)는 파라미터가 넘어올 때, 원본 데이터의 주소값을 넘기는 방식이다. 파라미터가 원본 데이터의 "주소값"을 가리키고 있기 때문에, 데이터를 변경하면 원본 데이터도 같이 변경된다는 특징이 있다.
Java에서의 Pass-By-Value
그렇다면 왜 Java는 Pass-By-Value로 동작한다는 것인지, 앞서 소개한 문제를 토대로 하나씩 설명해보겠다.
Java Runtime Data Area에는 Method Area, Heap Area, Stack Area, PC register, Native Method Stack이 있지만, 객체와 지역 변수간의 설명을 위해 Stack과 Heap을 준비해보았다.
- Stack Area : 지역변수, 파라미터, 리턴 값, 연산에 사용되는 임시 값 등이 생성되는 영역
- Heap Area : new 키워드로 생성된 객체와 배열이 생성되는 영역
public static void main(String[] args) {
int x = 10;
int[] arr = new int[]{1, 2, 3};
Person person1 = new Person("여민수");
Person person2 = person1;
...
}앞서 소개한 문제의 main 함수에서는 다음과 같은 필드 변수가 선언되었다.
- x : primitive 타입의 int형 변수
- arr : int형 배열을 가지는 참조 변수
- person1 : new 키워드로 생성 된 Person 객체 참조 변수
- person2 : person1의 데이터를 복사한 참조 변수

스택에서 보이는 좌측부터 변수 이름, 주소값, 실제 데이터 값이다.
설명의 편의상 주소값을 0a, 0b, 1a, 1b 등과 같이 나타냈을 뿐 실제는 이와는 전혀 다른 주소값이므로 주의 바란다.
main 메소드에서 선언 된 변수 순서대로 스택에 저장되었다. x는 primitive 타입이므로 선언된 값 그대로 스택에 저장되었고, 배열과 객체는 힙에 저장된 후, 스택에서 해당 객체를 참조하는 주소값이 저장되어 있다.
public static void main(String[] args) {
...
foo(x, arr, person1);
...
}
static void foo(int x, int[] arr, Person person) {
...
}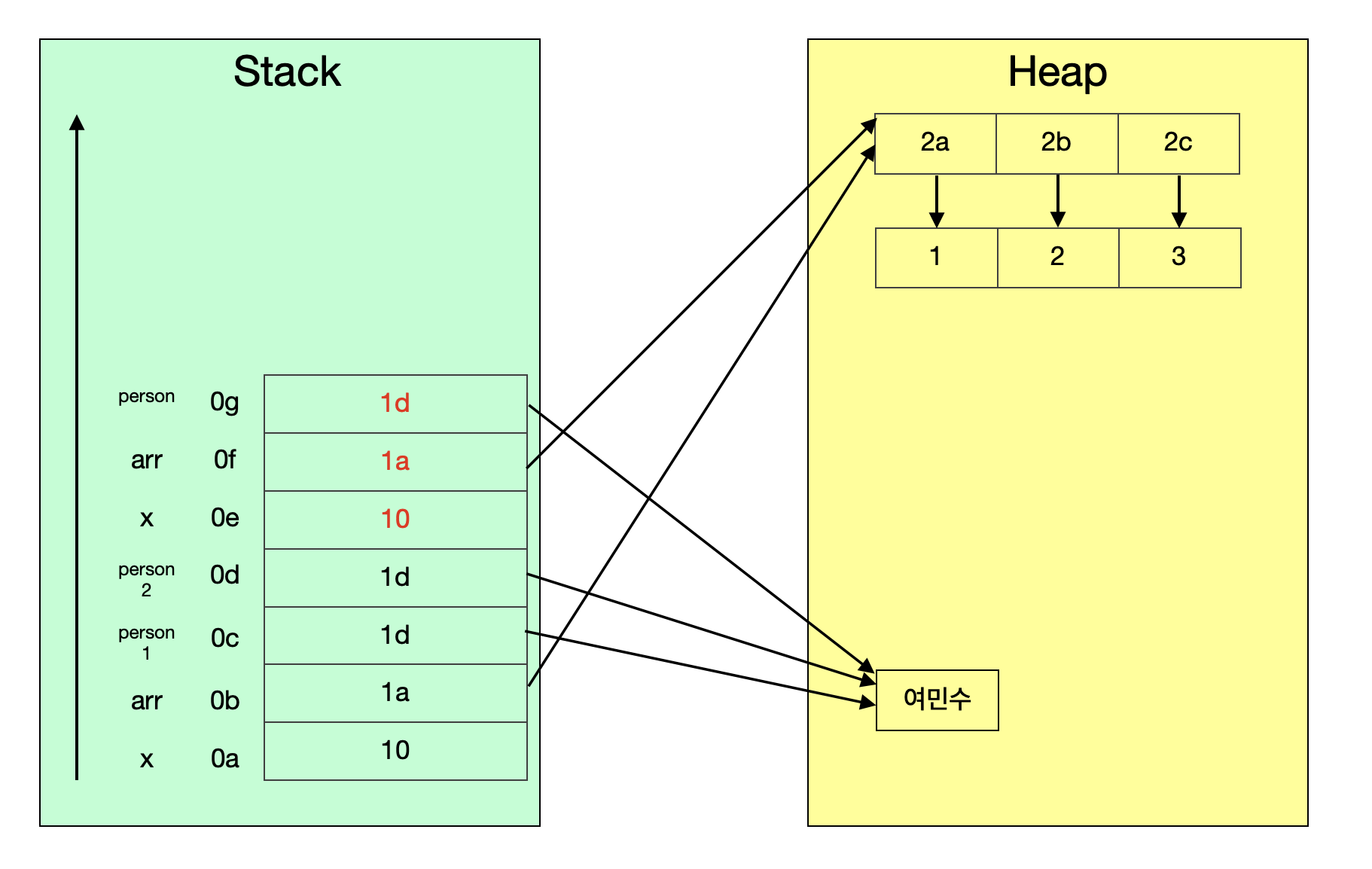
foo 메소드의 파라미터 x, arr, person이 Pass-By-Value에 따라 파라미터로 넘긴 데이터의 값(value)를 그대로 복사해서 스택에 저장된 것을 알 수 있다.
(만약 Java가 Pass-By-Reference로 동작했다면 스택의 0e, 0f, 0g 자리에 각각 0a, 0b, 0c가 저장되었어야 할 것이다.)
static void foo(int x, int[] arr, Person person) {
x ++;
arr[0] = 100;
person = new Person("김병수");
// 1
System.out.println("#1 " + person.getName());
person.setName("김준서");
}이제 foo 메소드의 동작에 따라 스택과 힙이 어떻게 동작하는지 보자.

x++에 따라 파라미터로 복사된 데이터인 0e의 주소값의 데이터가 11로 변경된다.arr[0]에 따라 파라미터로 복사된 데이터인 0f가 가리키고 있는 힙의 배열 1a로 이동하고, 0번 인덱스를 수정하기 위해 2a의 데이터를 100으로 변경한다.new Person("김병수")에 따라 힙에 새로운 객체를 생성하고, 해당 파라미터는 새로 생성된 김병수 객체인 1e를 가리킨다.

- 아직 foo 메소드가 종료하지 않았으므로,
person.setName("김준서")에 따라 파라미터 person이 가리키는 객체 1e의 값이 김준서로 변경된다.

드디어 foo 메소드가 종료되었다.
스택 영역은 아까 이야기했듯이 지역변수, 파라미터, 리턴 값, 연산에 사용되는 임시 값 등이 생성되는 영역이므로, 메소드가 종료되면서 할당되었던 파라미터들이 모두 사라졌다.
힙 영역은 GC 대상이므로 사용하지 않는 김준서 객체는 GC에 의해 제거될 것이다.
이에 따라, 다음과 같은 결과값이 나올 수 있는 것이다.
#1 김병수
#2 10
#3 [100, 2, 3]
#4 여민수
#5 여민수더하여
만약 foo 메소드 내에서, new 키워드를 사용하지 않고 setName 메소드를 호출하면 어떻게 될까?
static void foo(int x, int[] arr, Person person) {
x++;
arr[0] = 100;
person.setName("김준서");
//1
System.out.println("#1 " + person.getName());
}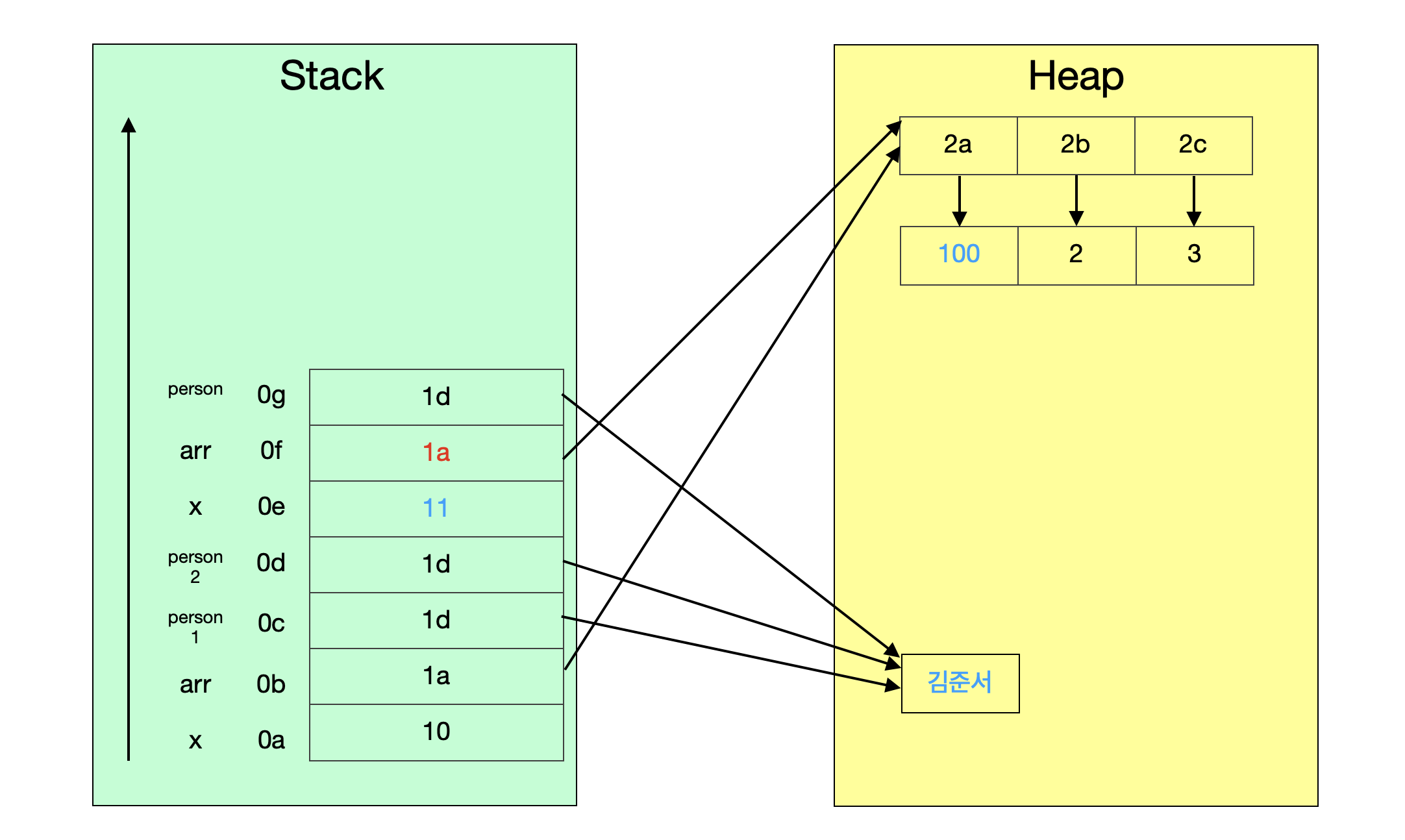
파라미터 person이 새로운 객체를 저장하지 않으므로, 원본 데이터인 1d를 그대로 갖고 있음에 따라, 1d 객체의 데이터가 김준서로 변경될 것이다.
#1 김준서
#2 10
#3 [100, 2, 3]
#4 김준서
#5 김준서